대회 기간은 한 주밖에 안되고, 이걸 하나하나 코드로 짜기엔 대회 기간 내에 완성 못 할까봐 겁이나고 미루고 미루다가 대회 종료 이틀 남겨두고 작성한 코드다.
좀 더 일찍 뛰어들어볼 걸 싶으면서 아주 후회된다. 하지만 높은 점수를 내는 것보다 공부할 기회가 주어졌음에 감사하자.
대회 진행을 위해서는 ufo format을 써야한다.
ufo 파일에는 tag가 달리고
coco 파일에는 tag의 존재가 없다. 물론 새로 tags나 container 같은 새로운 key를 추가해줘도 되지만
CVAT에서 relabeling 작업을 거쳐 출력된 새로운 coco format json에서는 tag, container같은 default 인자 외의 값은 모두 삭제된다.
tag를 다는 코드도 있긴 하지만 페이지 수만 잡아먹을 것 같고 필요하지도 않으니 그냥 tag(='masked', 'excluded-region', 'maintable', 'stamp')를 무시하고 포맷을 변경하는 코드만 기록해둬야겠다.
공공행정문서를 ufo 포맷으로 바꾸기 위해서는
1.1 → 자료 다운로드
1.2 → 이미지와 별개의 json파일 정리하여 합치기
1.3 → coco 포맷으로 변경하기
1.4 → cvat에서 label확인하고 coco포맷으로 export하기
1.5 → coco포맷을 ufo로 변환하기
1.6 → 기존 train json과 concat 하기 (concat하지 않고 pth 파일만 받아와서 훈련을 이어가도 된다.)
의 과정을 거치면 된다.
1.1 AiHub 에서 자료 다운로드 받기
aihub에 회원가입하고 접속해서 ai 데이터 찾기에 가면
[ 한국어 → 이미지 ] 에 접속해서 다양한 데이터를 볼 수 있다.
나는 <공공행정문서ocr> 과 <OCR 데이터(금융 및 물류)> 를 열람했다.
<공공행정문서ocr>는 모든 글자에 labeling이 돼있는데
<OCR 데이터(금융 및 물류)> 는 항목에는 labeling이 돼있지 않고, 손글씨에만 labeling이 돼있어서 제외했다.
(기껏 format 변경하고 cvat로 확인했더니 저랬다... 배신당한 기분이었다...)

어쩃거나
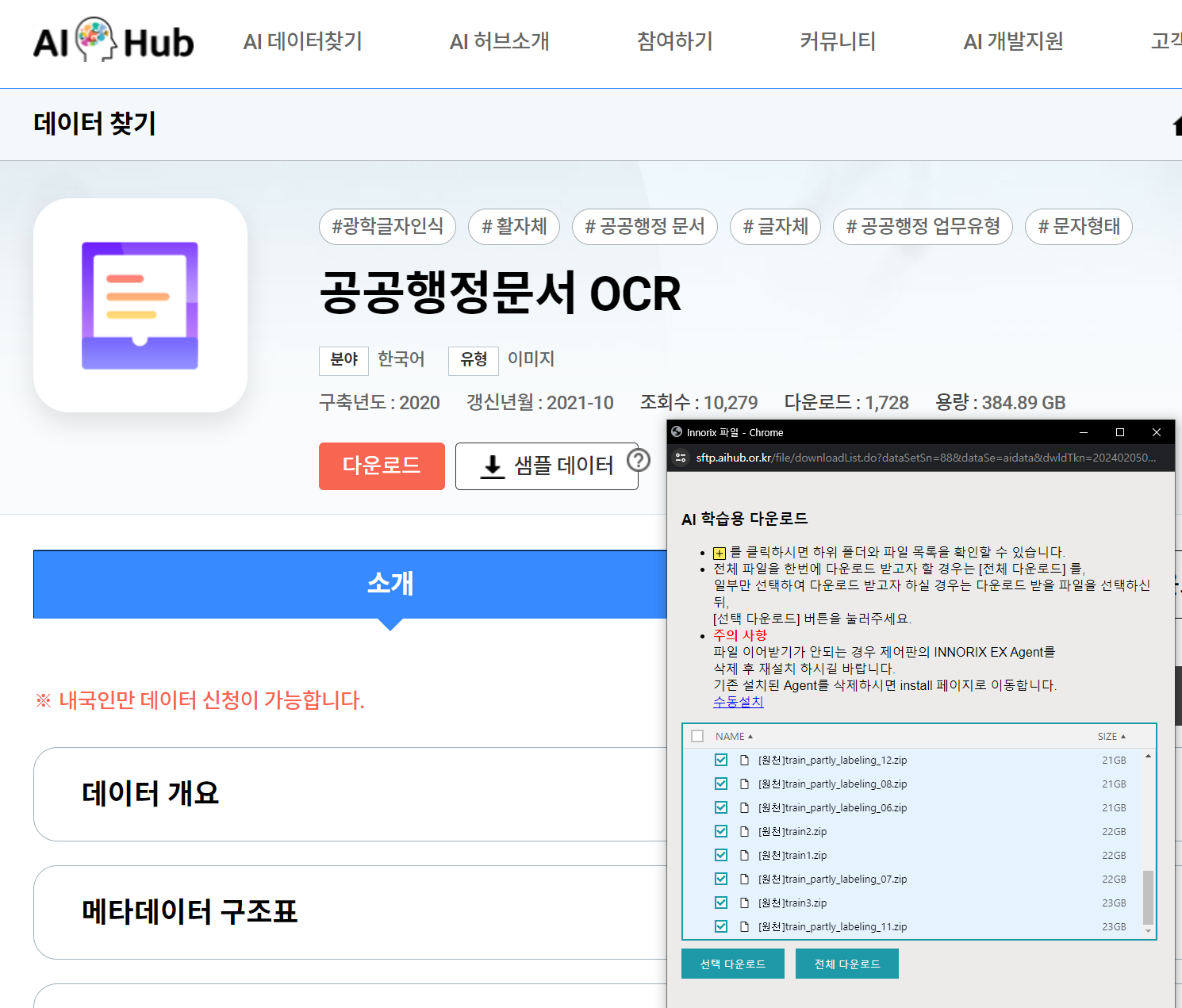
다운로드 버튼을 누르면 다운로드 프로그램을 설치하고 이렇게 나온다.
냉큼 전체 다운로드 누르면 큰일난다.
조심해야한다. 이거 전체 다운로드하면 384GB 자료 다운받는 거다.
그 큰 일을 내가 해냈다.
폴더는 크게 train, valid로 나뉜다.
train 안에는 크게 train과 train_partly_labeling이 있다. train_partly_labeling이건 뭔지 모르겠다.
[라벨]train 안에는 [원천]train 1, [원천] train 2, [원천] train 3에 대한 json파일이 담겨있다.
[라벨]train, [원천]train 1 만 다운로드 받아도 이미지가 1만6천장 쯤 존재한다.
나는 뭘 다운로드 받았는지 기억안나기 때문에 그냥 작성된 코드로만 기록을 남겨둔다.
1.2 이미지와 별개의 json파일 정리하여 합치기
[라벨]train, [원천]train 1을 다운로드 받았을 때 폴더 구조가 복잡하다.
이미지의 총 개수를 세고싶다면 walk 함수를 써서
jpg_file_count = 0
folder_to_search = "../data/medical/OCR/02.원천데이터(Jpg)"
for root, dirs, files in os.walk(folder_to_search):
for file in files:
if file.endswith(".jpg"): # 확장자 jpg 검색
jpg_file_count += 1
print(jpg_file_count)이렇게 간단하게 셀 수 있다.
그리고 각각의 이미지마다 json파일이 존재하므로
일단 새로운 폴더에 이미지와 json파일을 옮겨놔야한다.
나는 눈으로 선별하여 54개의 이미지를 '../data/medical/OCR/img' 에 저장해두고
이미지와 동일한 이름을 가진 json파일을 '../data/medical/OCR/json에 복사할 것이다.
import os
folder_path = '../data/medical/OCR/img' # 폴더 경로
files_ext = os.listdir(folder_path) # 폴더 내의 파일 목록
# 확장자를 제외한 파일명만 추출
img_files = [os.path.splitext(file)[0] for file in files_ext]
len(img_files)>> 54
이렇게 img_files에 파일명을 저장하고, json을 가져오는 조건으로 이용할 것이다.
import os
import shutil
# 원본 json 파일이 있는 폴더
json_source_folder = "../data/medical/OCR/01.라벨링데이터(Json)"
# 이동시킬 폴더
destination_json_folder = "../data/medical/OCR/json"
# json 파일을 복사하며 이미지 파일과 동일한 이름인 경우에만 복사
for root, dirs, files in os.walk(json_source_folder):
for file in files:
if file.endswith(".json"):
source_file_path = os.path.join(root, file)
destination_json_name = os.path.splitext(file)[0] # 확장자 제외한 파일 이름만 가져오기
destination_json_path = os.path.join(destination_json_folder, file)
if destination_json_name in img_files: # list에 저장된 이름이라면 복사
shutil.copy(source_file_path, destination_json_path)
json_folder_path = '../data/medical/OCR/json' # 복사가 잘됐는지 확인
json_files_ext = os.listdir(json_folder_path)
len(json_files_ext)>> 54
이렇게 json파일이 복사된다.
1.3 coco 포맷으로 변경하기
이제 json을 합치고 coco format으로 변경해보자.
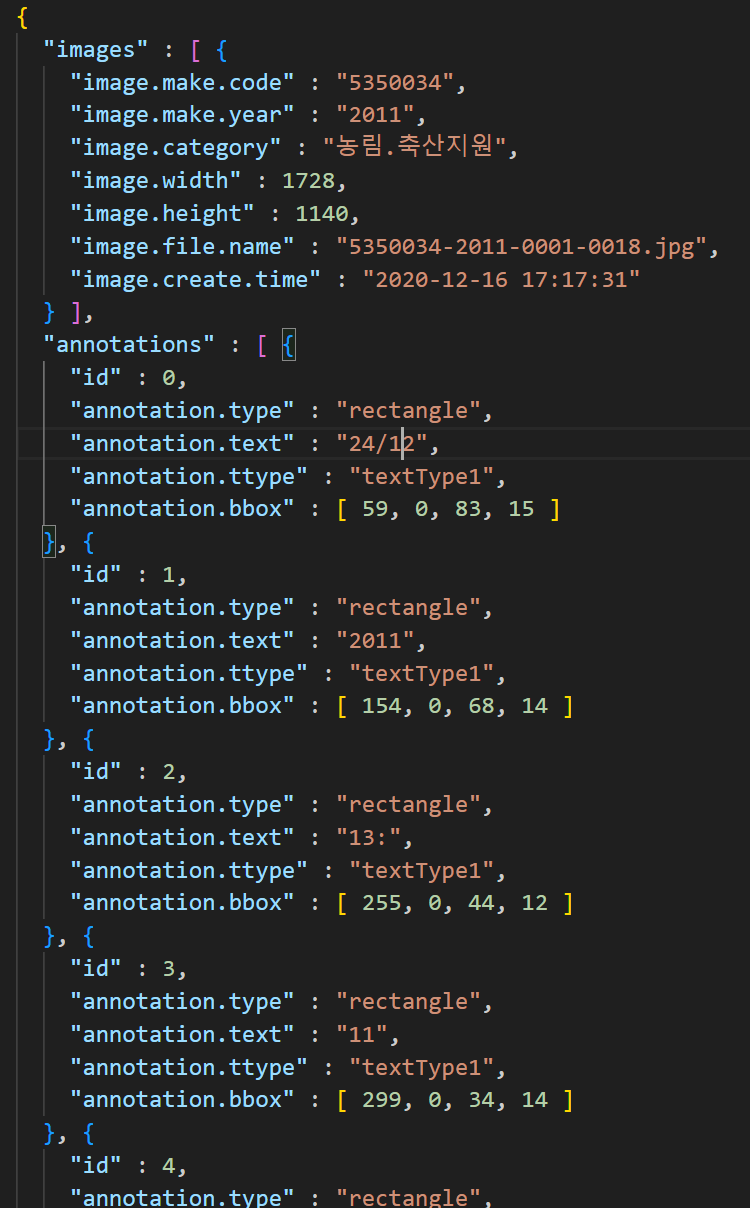
각각의 json파일은 이렇게 돼있다. 이건 coco 포맷이라고 보긴 다소 힘들 것 같다.
한편, 각 리스트의 값은 [min x, min y, w, h]이다.
coco 포맷을 바꾸면서 다른 json파일들과 병합해주는 게 편하다.
한편 cvat에서는 segmentation 인자도 받아와야하기 때문에 대충 ufo포맷의 x1y1, x2y2, x3y3, x4y4 값을 넣어두자.
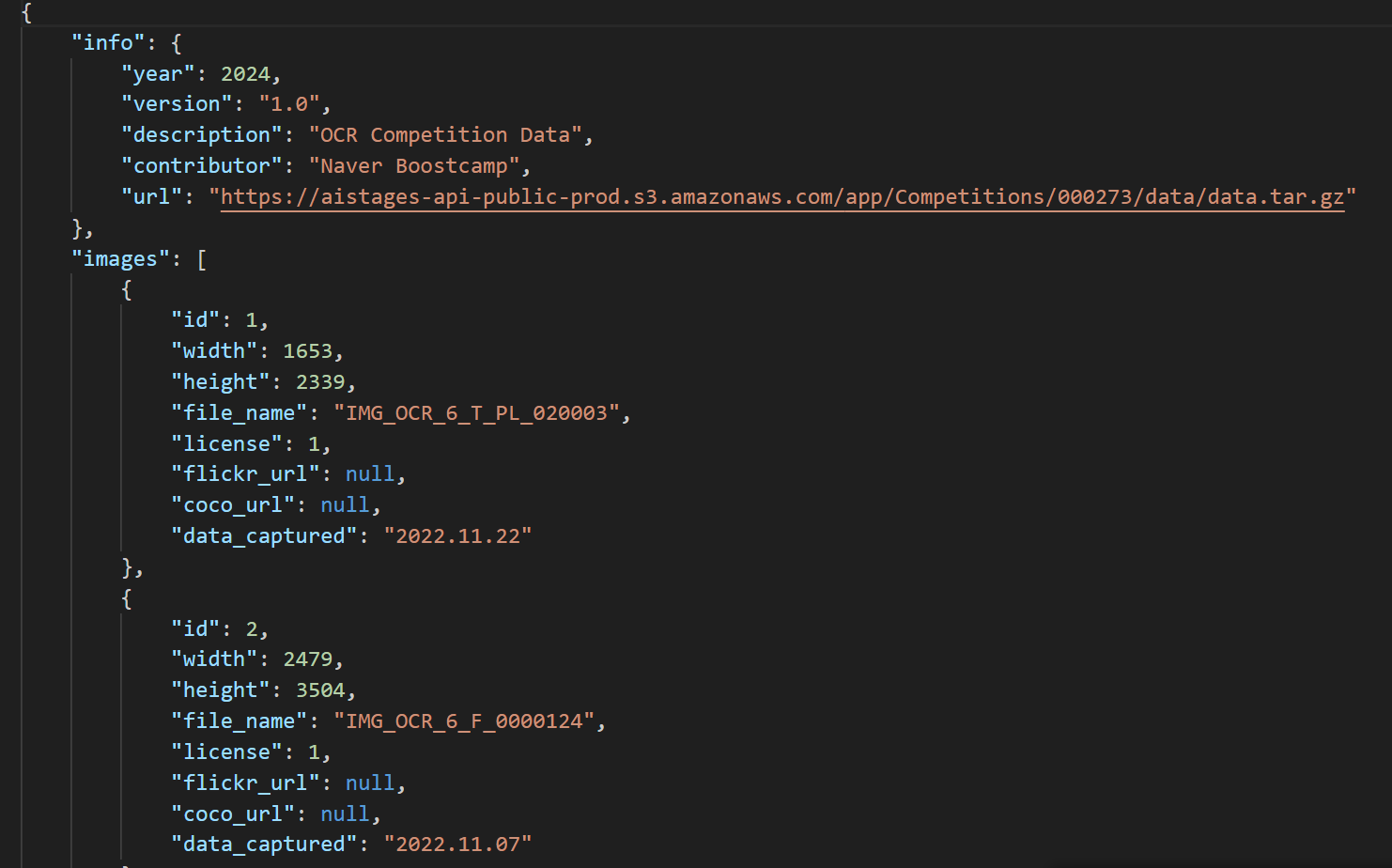
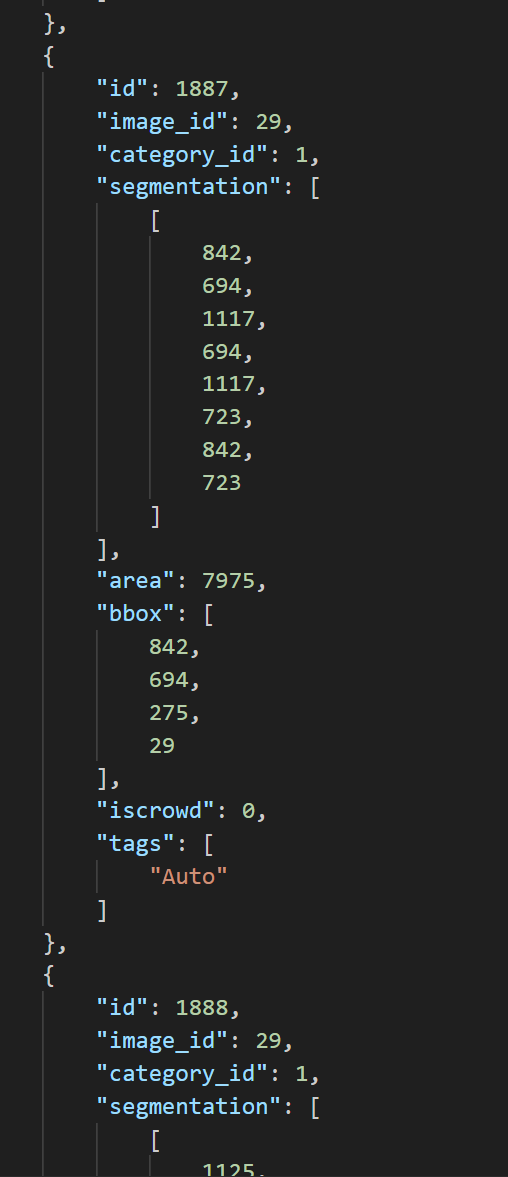
이런 식으로 바꿔줘야 cvat에서 인식하는 coco 1.0 포맷이 된다.
각 파일을 순환하며, image_name, xywh를 받아오고 image id, annotations id를 생성해야한다.
import json
import os
# JSON 파일이 있는 폴더 경로
json_folder = '../data/medical/OCR/json/'
output_path = '../data/medical/ufo/new_json.json'
# 기존 정보
info = {
'year': 2024,
'version': '1.0',
'description': 'OCR Competition Data',
'contributor': 'Naver Boostcamp',
'url': 'https://aistages-api-public-prod.s3.amazonaws.com/app/Competitions/000273/data/data.tar.gz',
}
licenses = {
'id': '1',
'name': 'For Naver Boostcamp Competition',
'url': None
}
categories = [{'id': 1, 'name': 'word'}]
# COCO 데이터 초기화
img_id = 1 # coco는 1번부터 시작한다.
annotation_id = 1
images = []
annotations = []
for file_name in os.listdir(json_folder):
if file_name.endswith('.json'):
input_path = os.path.join(json_folder, file_name)
with open(input_path, 'r') as f:
file = json.load(f)
image = {
'id': img_id,
'width': file['images'][0]['image.width'],
'height': file['images'][0]['image.height'],
'file_name': file['images'][0]["image.file.name"],
"license": 1,
"flickr_url": None,
"coco_url": None,
'data_captured': file['images'][0]["image.create.time"]
}
images.append(image)
for ann_info in file['annotations']:
min_x = ann_info["annotation.bbox"][0]
min_y = ann_info["annotation.bbox"][1]
width = ann_info["annotation.bbox"][2]
height = ann_info["annotation.bbox"][3]
segmentation = [
[min_x, min_y, min_x + width, min_y, min_x + width, min_y + height, min_x, min_y + height]
]
coco_annotation = {
"id": annotation_id,
"image_id": img_id,
"category_id": 1,
"segmentation": segmentation,
"area": width * height,
"bbox": [min_x, min_y, width, height],
"iscrowd": 0,
'tags' : ['Auto']
}
annotations.append(coco_annotation)
annotation_id += 1
img_id += 1
# 모든 데이터를 COCO 포맷으로 합치기
coco = {
'info': info,
'images': images,
'annotations': annotations,
'licenses': licenses, # 리스트로 변환
'categories': categories
}
# JSON 파일로 저장
with open(output_path, 'w') as f:
json.dump(coco, f, indent=4)
# KeyError 0 나면, new_json.json가 이미 만들어져 있는 거임.새로 생성된 json이 54개의 json파일이 있는 공간에 생성된다면 당연히 이 코드는 오류가 날 것이다.
54개의 파일과 새로생긴 1개의 파일이 format이 다르니...
나는 이 오류로 하루를 버려먹고
output_path = '../data/medical/ufo/new_json.json' 를 수정함으로써 해결했다 (바보인가...)
어쨋거나 이렇게 하면 coco format의 json파일이 생성된다.
1.4 cvat에서 label확인하고 coco포맷으로 export하기
이걸 CVAT에서 수정하고 다시 UFO로 돌아오면 된다.
1.5 coco포맷을 ufo로 변환하기
from typing import Dict
import json
import datetime
now = datetime.datetime.now()
now = now.strftime('%Y-%m-%d %H:%M:%S')
# 커스텀 coco포맷 json파일 -> ufo포맷
# input_path = '/data/ephemeral/home/level2-cv-datacentric-cv-10/data/medical/ufo/new_json.json'
# output_path = '/data/ephemeral/home/level2-cv-datacentric-cv-10/data/medical/ufo/_new_json.json'
# cvat작업 coco포맷 json파일 -> ufo포맷
input_path = '/data/ephemeral/home/level2-cv-datacentric-cv-10/data/medical/ufo/instances_default.json'
output_path = '/data/ephemeral/home/level2-cv-datacentric-cv-10/data/medical/ufo/_instances_default.json'
ufo = {
'images': {}
} # 여기에 모든 데이터를 저장할 거다cvat 작업을 하고나면 instances_default.json으로 저장되길래, 그냥 이렇게 해뒀다.
이건 편하신 대로 바꿔쓰자.
def coco_bbox_to_ufo(bbox):
min_x, min_y, width, height = bbox
return [
[min_x, min_y],
[min_x + width, min_y],
[min_x + width, min_y + height],
[min_x, min_y + height]
]
def coco_to_ufo(file: Dict, output_path: str) -> None:
anno_id = 1
for annotation in file['annotations']:
file_info = file['images'][int(annotation['image_id'])-1]
image_name = file_info['file_name']
if image_name not in ufo['images']:
anno_id = 1
ufo['images'][image_name] = {
"paragraphs": {},
"words": {},
"chars": {},
"img_w": file_info["width"],
"img_h": file_info["height"],
"tags": ["autoannotated"],
"relations": {},
"annotation_log": {
"worker": "",
"timestamp": now,
"tool_version": "LabelMe or CVAT",
"source": None
},
"license_tag": {
"usability": True,
"public": False,
"commercial": True,
"type": None,
"holder": "Upstage"
}
}
# anno_id = 1
ufo['images'][image_name]['words'][str(anno_id).zfill(4)] = {
"transcription": "",
"points": coco_bbox_to_ufo(annotation["bbox"]),
"orientation": "Horizontal",
"language": None,
"tags": ['Auto'],
"confidence": None,
"illegibility": False
}
anno_id += 1
with open(output_path, "w") as f:
json.dump(ufo, f, indent=4)
with open(input_path, 'r') as f:
file = json.load(f)
coco_to_ufo(file, output_path)이렇게 하면 ufo파일이 생성된다.
1.6 기존 train json과 concat 하기
# 기존 json
original_json_path = '../data/medical/ufo/train.json'
# custom_json파일
made_json_path = '../data/medical/ufo/_instances_default.json'
import json
with open(original_json_path, 'r') as f:
file_1 = json.load(f)
with open(made_json_path, 'r') as f:
file_2 = json.load(f)
output_path ='../data/medical/ufo/_newest_.json' # 로 저장된다.
combined_images = {}
combined_images = {**file_1['images'], **file_2['images']}
combined_json = {
'images': combined_images
}
with open(output_path, "w") as f:
json.dump(combined_json, f, indent=4)
len(file_1['images'])>> 100
len(file_2['images'])>> 54
len(combined_json['images'])>> 154
꼭 확인해주자. 한번씩 헷갈려서 잘못 합칠 때가 있다.
===========================================================================
언젠가 사용하게될지도 모를, OCR 데이터(금융 및 물류) 데이터의
coco format, ufo format 변환 코드를 기록해둬야겠다.
custom → coco
info = {
'year': 2024,
'version': '1.0',
'description': 'OCR Competition Data',
'contributor': 'Naver Boostcamp',
'url': 'https://aistages-api-public-prod.s3.amazonaws.com/app/Competitions/000273/data/data.tar.gz',
}
licenses = {
'id': '1',
'name': 'For Naver Boostcamp Competition',
'url': None
}
categories = [{
'id': 1,
'name': 'word'
}]
import json
import os
# JSON 파일이 있는 폴더 경로
json_folder = '../data/medical/sample_ocr/json/'
output_path = '../data/medical/ufo/add_json.json'
# 기존 정보
info = {
'year': 2024,
'version': '1.0',
'description': 'OCR Competition Data',
'contributor': 'Naver Boostcamp',
'url': 'https://aistages-api-public-prod.s3.amazonaws.com/app/Competitions/000273/data/data.tar.gz',
}
licenses = {
'id': '1',
'name': 'For Naver Boostcamp Competition',
'url': None
}
categories = [{'id': 1, 'name': 'word'}]
# COCO 데이터 초기화
img_id = 1
annotation_id = 1
images = []
annotations = []
for file_name in os.listdir(json_folder):
if file_name.endswith('.json'):
input_path = os.path.join(json_folder, file_name)
with open(input_path, 'r') as f:
file = json.load(f)
image = {
'id': img_id,
'width': file['Images']['width'],
'height': file['Images']['height'],
'file_name': file['Images']["identifier"],
"license": 1,
"flickr_url": None,
"coco_url": None,
'data_captured': file['Images']["data_captured"]
}
images.append(image)
for ann_info in file['bbox']:
min_x = min(ann_info["x"])
max_x = max(ann_info["x"])
min_y = min(ann_info["y"])
max_y = max(ann_info["y"])
# width와 height 계산
width = max_x - min_x
height = max_y - min_y
segmentation = [
[min_x, min_y, max_x, min_y, max_x, max_y, min_x, max_y]
]
coco_annotation = {
"id": annotation_id,
"image_id": img_id,
"category_id": 1,
"segmentation": segmentation,
"area": width * height,
"bbox": [min_x, min_y, width, height],
"iscrowd": 0,
'tags' : ['Auto']
}
annotations.append(coco_annotation)
annotation_id += 1
img_id += 1
# 모든 데이터를 COCO 포맷으로 합치기
coco = {
'info': info,
'images': images,
'annotations': annotations,
'licenses': licenses, # 리스트로 변환
'categories': categories
}
# JSON 파일로 저장
with open(output_path, 'w') as f:
json.dump(coco, f, indent=4)
# KeyError 0 나면, new_json.json가 이미 만들어져 있는 거임.
coco → ufo
from typing import Dict
import json
import datetime
now = datetime.datetime.now()
now = now.strftime('%Y-%m-%d %H:%M:%S')
# 커스텀 coco포맷 json파일 -> ufo포맷
# input_path = '../data/medical/ufo/add_json.json'
# output_path = '../data/medical/ufo/_add_json.json'
# cvat작업 coco포맷 json파일 -> ufo포맷
input_path = '../data/medical/ufo/instances_default.json'
output_path = '../data/medical/ufo/_instances_default.json'
ufo = {
'images': {}
}
def coco_bbox_to_ufo(bbox):
min_x, min_y, width, height = bbox
return [
[min_x, min_y],
[min_x + width, min_y],
[min_x + width, min_y + height],
[min_x, min_y + height]
]
def coco_to_ufo(file: Dict, output_path: str) -> None:
anno_id = 1
for annotation in file['annotations']:
file_info = file['images'][int(annotation['image_id'])-1]
image_name = file_info['file_name']
if image_name not in ufo['images']:
anno_id = 1
ufo['images'][image_name] = {
"paragraphs": {},
"words": {},
"chars": {},
"img_w": file_info["width"],
"img_h": file_info["height"],
"tags": ["autoannotated"],
"relations": {},
"annotation_log": {
"worker": "",
"timestamp": now,
"tool_version": "LabelMe or CVAT",
"source": None
},
"license_tag": {
"usability": True,
"public": False,
"commercial": True,
"type": None,
"holder": "Upstage"
}
}
# anno_id = 1
ufo['images'][image_name]['words'][str(anno_id).zfill(4)] = {
"transcription": "",
"points": coco_bbox_to_ufo(annotation["bbox"]),
"orientation": "Horizontal",
"language": None,
"tags": ['Auto'],
"confidence": None,
"illegibility": False
}
anno_id += 1
with open(output_path, "w") as f:
json.dump(ufo, f, indent=4)
with open(input_path, 'r') as f:
file = json.load(f)
coco_to_ufo(file, output_path)'Lectures > BoostCamp -Naver' 카테고리의 다른 글
| level 2 Data-Centric, 9. numpy, albumentation 버전에 따른 훈련속도 차이 변화 12분 → 3분 (1) | 2024.02.05 |
|---|---|
| level 2 Data-Centric, 7. CORD (clova, huggingface) 사용법 (coco ↔ ufo) (1) | 2024.02.05 |
| level 2 Data-Centric, 3. CVAT 사용법 (labeling tool) (0) | 2024.02.05 |
| level 2 Data-Centric, 2. makeing validset (2) | 2024.02.05 |
| level 2 Data-Centric, 0. img위에 annotations 시각화 (1) | 2024.02.05 |


댓글