DETR(Detection with Transformers)
DETR 이전에는 YOLO, 와 Faster R-CNN이 대표적인 Image Detector였다. 각자의 특징은 따로 포스팅으로 언급하도록 하겠다. DETR이 앞선 연구와 차별점이 있다면, 이미지 분석에 transformer를 적용했다는 점이다.
(이번 포스팅을 준비하면서 알게된 점이지만, DETR는 2020년 3월 26일에 공개된 것으로, VIT보다 앞선 연구였다.! )

0. Bipartite Mathching
DETR에서 중요한 개념을 고르자면 Bipartite matching(이분 매칭)과 Transformer,,가 될 것 같고,
생소할 수 있는 개념을 고르자면 IoU와 GIoU이다.
하나씩 짚고 본론으로 가자.
Bipartite matching은 두 집단 간의 사다리를 가장 많이 연결하는 방법을 찾아내는 알고리즘이다.

이런 A집단에서 B집단으로 사다리를 연결할 때, 가장 많이 연결하기 위해서는
A-1, B-2, C-5, D-3 으로 그리고 E는 연결이 불가능하다. 최대 4개가 되는 것이다.
(보통 집합B가 어떤 수치와 연결돼 있어서, sum이 최댓값, 최솟값을 갖도록 하는 순열을 찾을 때 쓰인다.)
Transformer는 앞선 포스팅을 참고하도록 하자.
Transformer
개인적으로 transformer를 공부하면서 이해했다싶으면 또 갸우뚱하는 지점이 생기고, 다른 블로그나 유튜브 영상을 보면 예시가 내가 이해한 거랑 좀 다른 것 같았다. 지식을 공유하는 목적이기보
yooom.tistory.com
GIoU도 포스팅을 참고하도록 하자ㅋㅋ
IoU, GIoU, DIoU 개념 !
DETR을 공부하다보니 Bounding Box를 갱신하는 과정에서 처음 듣는 용어가 나와서 정리해둔다. ! IoU : 교집합 / 합집합 GIoU : 두 박스의 합집합 / 두 박스를 포함하는 큰 박스 넓이 DIoU : IoU, 두 박스 중
yooom.tistory.com
개념 끝. 바로 본론에 들어가보자. ㅎㅎ
Architecture of DETR

DEtector with TRansformer의 전반적인 흐름은 위의 그림과 같다.
- CNN으로 Feature map을 생성하여 transformer에 input한다.
- attention으로 사물간의 관계를 파악한다.
- prediction을 set으로 중복을 제거하여 bipartite matching을 한다.
좀 더 세부적으로 보자.
DETR의 흐름은 크게 네 가지 구획으로 나뉜다.

1. backbone ( input data )
vit에서는 하이브리드로 feature map을 사용해도 괜찮다고 했지만, DETR에서는 곧장 feature map을 쓴다!
각 feature map이 transformer를 통과할 수 있게 flatten 해주고 positional embedding을 해준다.

CNN(resnet50, resnet100)을 통해 feature map을 뽑아낸 뒤 \( (3, W_{0} ,H_{0}) \)의 이미지를 \((2048, W, H)\) 로 만든다.
\(W=\frac{W_{0}}{32}, H=\frac{H_{0}}{32} \)
>> 예시로는 3 x 512 x 512 이미지를 2048 x 16 x 16 이미지로 만들었다 (512 / 32 = 16)
그 뒤 1x1 kernel을 이용하여 d차원으로 축소하여 ( d,W,H )가 된다.
한편, DETR에서는 d=256을 사용한다.
이미지의 각 픽셀을 flatten하여 HW개의 sequence를 얻어낸다.
2. Encoder

일반적인 transformer 구조와 동일하게 Multi-head Self Attention을 한 뒤 Add & Norm을 해준다. 그리고 (Feed Forward Neural Network)FFN를 통과한다.
완~전 내용이 동일하다.
다만 차이점이 좀 있다면 positional embedding이다. 여기에서만 차이점이 세 가지 있다. 화살표를 잘 보아라!
- positional embedding을 query, key에는 더해주고, value에는 더해주지 않는다.
( attention에서 query와 key는 서로 내적 → softmax 되는 관계였다 ! )
- 각각의 attention layer마다 positional embedding이 더해진다.
- vit에서는 1D, 2D positional embedding을 비교했지만, DETR에서는 2D fixed sine positional embedding만 사용한다.
▼ Positional Embedding을 간략하게 설명하려니 글이 길어져서 그냥 접었다.
2D fixed sine positional embedding이 tranformer에서와 어떤 차이를 가지는지 내가 이해한 대로 설명해놨다.
간략하게 positional embedding이 어떤 과정으로 나오냐 설명을 하자면, 전형적인 transformer positioanl embedding처럼 sin, cos 조합으로 position을 특정하는 것을 동일하다.
transformer 에서는
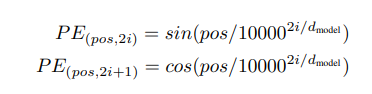
PE의 input이 sin과 cos에 각각
첫 번째 patch에서는 (0,0), (0,,1) // (0,2), (0,3) // (0,4), (0,5) // ...
두 번째 patch에서는 (1,0), (1,,1) // (1,2), (1,3) // (1,4), (1,5) // ...
세 번째 patch에서는 (2,0), (2,,1) // (2,2), (2,3) // (2,4), (2,5) // ...
이렇게 넣었다.
하지만 이번에는 조~금(?) 다른 값을 넣는다.
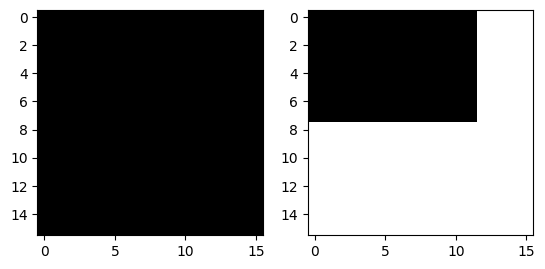
만일 이미지 size가 다르다면 오른쪽 그림처럼 padding을 넣어준다. 여기서 실제 이미지 위치에는 False를, padding 위에는 True가 나오게 mask를 씌운다.
~ mask 를 취하면 padding 부부은 False인 0이 된다. (왜 굳이 이렇게 했을까?ㅜ)
각각의 값에 cumsum을 해주면 누적합을 구할 수 있고, 이전 값과 변화가 없으면 padding부분으로 확정할 수 있다.
뭔말인지 모르갰으니깐 이미지 보자.
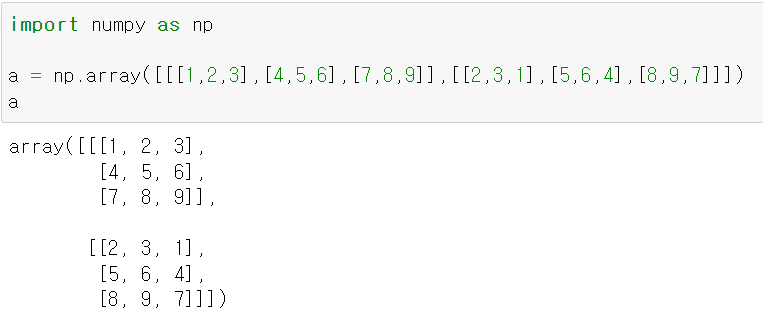
이런 3차원 공간을 만들었다.
cumsum(axis = ) 을 쓰면
cumsum 안의 parameter는 axis축이다 !

x, y 축으로의 누적합을 구할 수 있고, 이것을 토대로 정규화한다.
d=256차원이므로, x_dim = 128, y_dim=128 개를 구하여 concat 해준다.
개인적으로 유일성에 문제가 생기는 게 아닌가 싶지만 이건 나중에 해결하는 질문으로 남겨두자 !
참고하면 좋을 것 같은 곳은
https://itnext.io/detr-end-to-end-object-detection-with-transformers-part-1-4a7ec4e386f7
https://yooom.tistory.com/130
여길 참고하자 ㅋㅋ // 책임 떠넘기기 ㅜ


Encoding을 거친 뒤 output을 시각화 한 자료이고, Encoder의 layer 개수에 따른 AP에 대한 자료이다.
이미지를 보면 Encoding 단계에서 이미 충분한(?) 학습이 된 것처럼 보인다.
아래 표를 보면
\(AP_{S}\)에서 layer=0과 layer=3은 2밖에 차이나지 않지만
\(AP_{L}\)에서는 layer=0과 layer=3이 4 이상 차이난다.
큰 물체의 경계를 파악하는 데는 local한 특성을 가진 CNN보다 global한 특성을 가진 attention이 확실히 유리하다는 것을 알 수 있다.
3.Decoder

Decoder의 가장 하단 부 Multi-Head Self Attention layer는 NLP에서는 아주 중요한 과정 중 하나였다.
하지만 DETR에서는 있으나마나한 영향을 준다고 한다. (통일성? 간결성? 때문에 그냥 넣었다고 한다. )
이유는, Decoder의 input date가 set 파일이기 때문이다.
무슨 뜻이냐.
object간의 관계가 없고, 서로 독립된 자료라고 보는 것이다. 그래서 self attention할 게 없다.
설명 끝.
MultiHead Attention에서는 key와 value를 Encoder에서 받아온다.
Encoder에서 넘어온 data와 연관성을 조사한다.
이때 쓰이는 게 Bipartite matching이다 !

Decoder에서는 각각의 FFN을 거쳐 나온 data가 집합A에 들어가고, Ground Truth, Prediction을 집합 B에 넣어 matching을 조사한다.
실험은 COCO data set으로 진행했는데 object의 개수는 평균 n=7 이 된다고 한다. 설정된 slot은 N=100 이기 때문에
대부분의 예측 class가 \(\varnothing\) 라서 no object 인 class로 분류된다.
Faster R-CNN의 sub_samplling 유사한 빠른 연산을 위해 class=\(\varnothing\) 인 경우 weight를 1/10로 하여 학습한다고 한다.
loss 연산 과정을 살펴보자. (논문에 수식이 나와있으니깐...)

여기서 \(\hat{\sigma}\)는 Bipartite matching 시켜줄 여러가지 짝때기! 순열의 집합이다.
모든 순열에 대해 미리 loss를 계산한 다음 loss 가장 작은 애(→argmin)를 고르면 되니깐 backpropagation 과정에서 갱신되지 않는다. (이미 학습이 완료됐기 때문 !)
안에 \(\mathcal{L}_{match}\) 를 살펴보자.

\(y_{i}\)는 정답인 Ground Thruth이고 \(\hat{y}_{\sigma (i)}\)는 Bounding Box이다.
\( y_{i} \)는 \(y_{i} = (c_{i}, b_{i})\)로 구성돼 있는데,
\(c_{i}\)는 class이고, \(b_{i} = [0,1]^{4} = [x, y, W, H]\)로서
이미지 size에 따른 상대적인 xy좌표와 너비, 높이 값을 가지는 4-dim vector가 된다.
\(\hat{p}_{\sigma(i)}(c_{i})\)는 순열의 i번째 요소가 GT 클래스를 예측할 확률
\(\mathcal{L}_{box}\)는 순열의 i번째 요소가 GT와 box의 좌표와 크기의 loss 가 된다.
정리하자면,
\(\mathcal{L}_{match}\)는 작을 수록 예측을 잘 한 것이므로
\(\hat{p}_{\sigma(i)}(c_{i})\)는 예측을 잘 할 수록 큰 값을 내기 때문에 (-1)을 해주어 \(\mathcal{L}_{match}\)를 줄인다.
\(\mathcal{L}_{box}\)는 예측을 잘 할 수록 작은 loss를 내기 때문에 (+1)을 해주어 \(\mathcal{L}_{match}\)를 줄인다.
한번 더 들어가 \(\mathcal{L}_{box}\)에서는 GIoU로 Loss를 계산하는데 수식으로 적자면

이렇게 된다. 겁먹지 말자 별 거 아니다.
다시 바깥으로 튀어나와서, \(\mathcal{L}_{match}\)의 훈련을 보자.
\(\mathcal{L}_{Hungarian(y,\hat{y})}\)를 따로 정의하여 backpropagation 이전에 최대한 GT와 Bounding Box간의 loss를 줄이는 연산을 시켜준다.

순열 set에서 최소 조합을 찾아내는 hungarian알고리즘이다.
Hungaian algorithm
DETR 을 공부하다가 Loss을 계산하면서 Hungarian algorithm을 사용하는데 나 빼고 모두 아는 것처럼...슉 지나가버리길래 분노의 정리 글을 작성한다. ㅜ 상황을 가정해보자. 직원이 3명 있고, 작업이 3
yooom.tistory.com
참고 !
하여간 이렇게 Decoder에서 Bounding Box를 GT에 맞게 학습시킨다!
다음은 Decoder를 통과한 data가 어떻게 되는지 시각화한 이미지이다


왼쪽 표를 보면 Decoder layer가 깊어질 수록 AP는 늘어나지만, 일정 수준이 되면 cost 대비 output이 적어진다.
또한 NMS를 수행하냐 마냐의 차이는 아주 미미했다. ( Bipartite machting 덕분에 이미 잘 학습됐기 때문이다. )
Encoder보다는 확실히 경계 부분에 많은 attention을 주어 box boundary를 결정하는 데 큰 역할을 한다고 볼 수 있다.

COCO의 N=100 중 20 개의 Decoder output를 시각화한 것이다.
초록색은 작은 box, 빨간색은 가로로 큰 bos, 파란색은 세로로 큰 box를 의미한다.
전 영역에 분포하고, 화면의 대부분을 차지하고 있는 object라도 잘 포착하는 것을 확인할 수 있다.
Panotic Segmentation

DETR은 Detection 뿐만 아니라 Segmentation task도 사용될 수 있다고 한다. !
사용법은 masked head 하나만 추가하면 되는데,
위 이미지를 예시로 들자면 Decoder 에서 Bounding Box까지 만든 output을 가져온다.
이 경우, object가 4개가 된다 (소, 땅, 나무, 하늘)
Encoder에서 사용했던 feature map을 재사용하여 attention을 수행하여 뽑아낸 attention map과
Residual connection으로 더해준다 !

그러면 가장 오른쪽 그림처럼 segmentation이 된다고 한다.

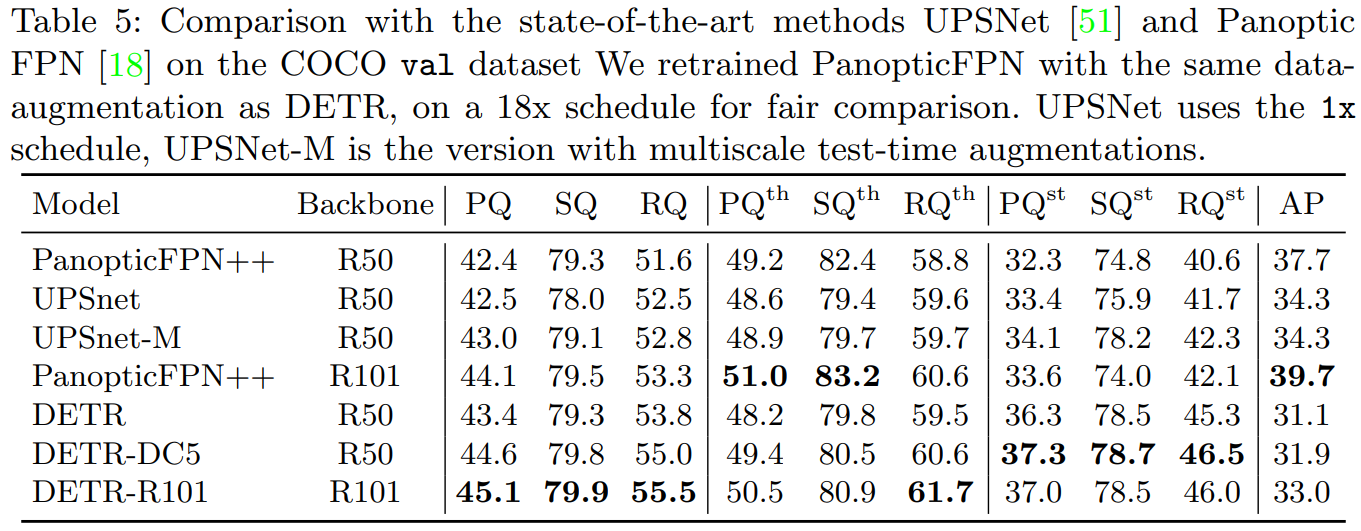
논문 출판 해에 2020년 당시 SOTA였던 PanopticFPN 보다 Segmentation task를 조금 더 잘 수행하고 있는 것을 알 수 있다
윗첨자 th는 thing, st는 stuff인데, thing은 비교적 작은 사물, stuff는 배경이 되는 하늘, 땅, 숲 이 된다.
thing의 segmentation은 PanopticFPN이 잘 수행하지만,
global한 task를 잘 수행하는 tranformer 특성 덕분에 stuff의 segmentation은 DETR이 훨씬 더 잘 수행한 것을 볼 수 있다.
참고
https://youtu.be/q1wSykClIMk?si=DECaZkl9zn54saEp
https://youtu.be/cQ5MsiGaDY8?si=5IzaVtSYGmDm9d3I