VIT는 이미지 분석에서 CNN에 사망선고 내릴 뻔 한 모델이라고 생각된다.
Attention으로 문장의 맥락파악에 이어 이미지의 맥락 파악에서 큰 힘을 발휘한 것이다.


오늘 이해할 내용은 VIT 과정 전체를 담은 이미지 하나와 수식 하나가 전부이다.
VIT와 관련된 사족은 모두 제쳐두고 내용의 이해와 논문 찍먹을 해보자.
1. Inductive bias의 이해
귀납 편향?? 이라고 해야할까.. 어떤 정보를 분석할 때 해당 정보가 어떤 정보의 특성을 띠는지 선입견을 가지고 처리하는 것이다. !
예를 들어
CNN은 kernel로 이미지를 위치별로 찍어 연산하기 때문에 locality와 transitional invanriance를 띤다.
RNN은 데이터가 시간적 특성을 띠고 있다고 가정하기 때문에 sequentialiy와 temporal invaiance를 띤다.
하지만 Tranformer는 이들과 다르게 그런 선입견(?)이 없다 ! 상대적으로 inductive bias가 작다
2. Model 의 이해
2-1 Split an image into fiexd-size patches
원본 이미지를 n개의 patch로 분해한다.
H x W x C 를 N x ( P x P x C ) 로 변환하는 과정이다.
2-2 Linear Projection of Flattened Patches
Patch (P x P x C)를 불러와 flatten시킨 뒤, Transformer로 사용할 수 있게 Embedding 과정을 거친다.
그러면 각 Patch는 P x P x C(row)에 D(col)가 추가된다. 즉, 요소의 수는 P x P x C x D 가 되겠다 !

이렇게 Embedding vector를 생성한다.
그냥 조금만 더 뜯어 보자.
위의 196개 Patch 중에 첫 번째만 가져와서 보자. ()16x16이지만 3x3 으로만 보자)

이렇게 각각의 Patch가 flatten되어 Embedding을 해주고, 맨 앞에 token을 추가해준다. 이 token은 최종적으로 MLP head에서 classification의 참고값이 된다.
내가 표현한 것처럼 RBG 값이 각 값의 ID가 되는지 확실치 않다 ㅜ
또한 같은 RBG 값을 가지면 Embedding이 같은 값인지도 확실하지 않다!
2-3 positional Embedding

VIT 에서는 4가지 Positional Embedding을 시도한 뒤, 가장 효과가 좋았던 1-D Pos. Emb를 Patch의 위치를 표현하는 데 이용함.
No Pos.Emb : Positional Embedding 적용 x
1-D Pos.Emb : 1차원 Embedding으로, patch를 Sequence data처럼 raster order방식으로 읽음.
2-D Pos.Emb : 2차원 Embedding으로, patch에 grid를 만들어 x,y값을 모두 이용함.
Rel Pos.Emb : patc들 사이의 상대적인 거리를 이용함.

2-3 Transformer Encoder

- Transformer Encoder는 Multihead Self Attention(MSA), MLP로 구성됨
- Reset 구조 처럼, residual connection을 해줌
- Attention is all you need 논문에서의 self-attention 구조는 multi-head atteition→ norm 순서였지만
Vit에서는 norm → multi-head atteition 순서로 이루어짐.
- MLP는 hidden layer와 single linear layer 2개가 있으며, 활성화 함수로 GELU를 사용함. pre-train할 때는 hidden layer를 하용하고 fine-tuning할 때는 single linear layer를 사용함.
2-4 정리된 수식 살펴보기

\(z_{0}\)은 가공된 input data를 의미하며, \(x^{N}_{p}\)은 N번 째 patch를 의미한다.
E는 Flatten시킨 P x P x C 개의 요소에 Embedding을 달아주는 함수이다. 즉, output으로 (PxPxC) x D 를 만들어 준다.
\(E_{pos}\)는 Positional Embedding이다. 각 Patch의 위치를 알려주는 값이며, 같은 Patch는 같은 Positional Embedding이 더해진다.
이때, 가장 첫 번째 패치의 Embedding 앞에 학습가능한 Embedding vector를 붙여준다. 결과적으로 이것으로 결과의 classification을 할 것이다.

객 패치인 \(z_{l-1}\) 은 ( \(l\)은 1~L이므로 \(l\)-1은 0~L-1 ) Layer Norm (LN)으로 입력된다.
LN에서는 위에서 살펴봤던 것처럼 Flatten을 시킨 후 Embedding과 Positional Embedding을 하여 Sequential form 으로 만든다.
Multihead Self Attention(MSA)에서는 Transformer을 본격적으로 이용하여 각 Seuquence를 Self Attention하여 관계를 밝혀낸다.

MLP는 pre-training 단계에서 hidden layer를 적용하고
fine-tuning 단계에서 single liear layer를 적용한다.
활성화함수로는 GELU를 사용한다.
hidden layer와 single linear layer가 어떤 걸 의미하는지는 좀 더 공부해봐야할 것 같다.

최종 결과값 중 가장 앞의 값인 \(z_{L}^{0}\)으로 classification을 진행한다.
Indictive bias 의 추가 설명
MLP는 locality와 translation equivariance가 확보되지만 (위치 데이터를 가진다는 뜻)
MSA는 CNN보다 inductive bias가 약하므로 locality의 확보를 위해 두 가지 방법을 사용했다.
1. patch 단위로 분해하여 positional embedding을 한다.
2. fine-tuning 단계에서 고해상도 이미지를 input으로 받았을 때, patch size는 동일하므로 patch 개수가 달라진다. 이때 공간 정보가 달라지므로 positional embedding을 변경하여 원본 이미지의 2D Pos Emb를 이용한다.
Hybrid Architecture
VIT는 raw image 뿐만 아니라 CNN으로 추출한 feature map을 활용할 수도 있음.
feature map은 이미 공간정보를 포함하고 있으므로 어떤 경우엔 patch size를 1x1로 이용할 수도 있으며, 이 때는 feature map을 flatten하여 embedding vector에 더해준다.
Fine-tunif and Higher Resolution
1. Lage dataset에서 VIT를 훈련한 뒤 downstream task에서 fine-tuning하여 사용.
2. fine-tuning할 때, 해결하고자 하는 downsteam task에 맞도록 VIT의 pre-trained prediction head제거하고 zero-initialized feedforward layer로 변경한다.
3. fine-tuning할 때, high resolution image를 사용하면 sequence가 길어지면서 pre-trained positional embedding의 공간 정보의 의미가 퇴색된다. 이를 방지하기 위해 원본 이미지의 공간 정보를 반영하여 2D Pos Emb를 사용함.
정리 : fine-tuning할 때는 MLP Head만 초기화한다. 고해상도 이미지를 사용할 때는 원본 2-D Pos Emb를 사용한다.
3. Experiments
3-1 data set

- class와 이미지 개수가 다른 3개의 data set을 이용하여 pre-train함.
- benchmark tast는 ReaL labels (Beyer et al., 2020), CIFAR-10/100 (Krizhevsky, 2009), Oxford-IIIT Pets (Parkhi et al.,
2012), and Oxford Flowers-102 (Nilsback & Zisserman, 2008), 그리고 추가적으로 VTAB classification suite (Zhai et al., 2019b) 를 downstream tast로 하여 성능을 검증함.

세 종류의 model을 실험하였으며, 각 모델에서 다양한 patch size로도 실험을 함.
Baseline CNN은 batch nomalization layer를 group normalization으로 변경, standardized convolutional layer를 transfer learning에 적합한 Big Transformer (IBT) 구조의 ResNet을 이용함.

실험에서 주목하는 model은 14x14 patch를 이용한 VIT-Huge와 16x16 patch를 이용한 VIT-Large이다.
data size가 가장 큰 JFT Data set에서 pre-train한 VIT-L/16 model이 기존의 SOTA였던 BIT-L보다 뛰어난 모습을 보여줌
VIT-L/14 model은 VIT-H/16 model보다 뛰어난 성능을 보여줬으며, BIT-L보다 학습시간도 훨씬 짧음

VTAB classification suite 을 3개의 그룹으로 나눠서 추가적인 실험을 함.
Natural – tasks like the above, Pets, CIFAR, etc
Specialized – medical and satellite imagery
Structured – tasks that require geometric understanding like localization.
전체 부문에서 VIT-H/14가 가장 뛰어난 것을 볼 수 있음.

본 실험에서는 pre-training data set의 크기에 따른 fine-tuning 성능을 확인함.
data size가 클 때 VIT가 BIT보다 성능이 좋았으며, 크기가 큰 VIT model이 성능이 좋았음
JFT를 각각 다른 크기로 랜덤 샘플링한 data set을 활용한 실험을 진행한 결과, data set이 작을 때는 inductive bias 덕분에 CNN이 효과적이지만, data set이 클 때는 데이터로부터 패턴을 학습하는 것으로도 충분함.
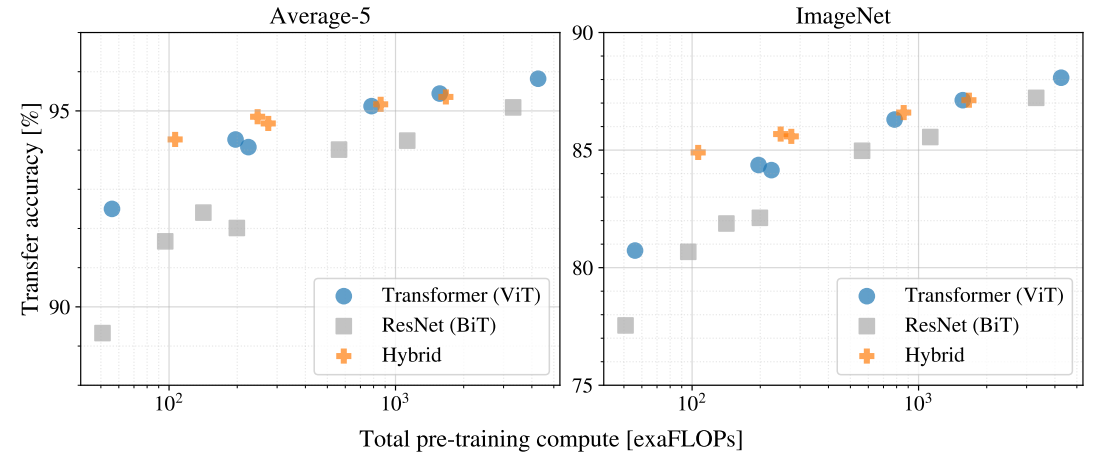
JFT를 기반으로 pre-train cost 대비 transfer 성능을 검증하여 model 별 scaling study를 함.
Pre-training cost : TPUv3 accelerator에서 모델의 inference 속도 관련 지표
VIT가 성능과 cost의 trade-off에서 ResNet(BIT) 보다 우세함.
cost가 증가할 수록 Hybrid와 VIT성능이 증가하고, cost와 trade-off 차이가 감소함
'Ai > Notion' 카테고리의 다른 글
| DETR(Detection with Transformers) (0) | 2023.11.08 |
|---|---|
| Transformer 에서 cos, sin 함수를 사용한 이유(position encoding) (0) | 2023.10.17 |
| Transformer (0) | 2023.10.12 |
| VggNet (0) | 2023.10.12 |
| AlexNet architecture (1) | 2023.10.10 |




댓글