1 INTRODUCTION

VggNet은 AelxNet에서 또 한번의 진보를 이끌어낸 모델이다. VggNet의 주된 시도는 최대한 많은 층을 쌓고 비선형 활성화함수를 사용하여 다양한 데이터에 유연하게 반응하는 것을 목표로 했다.
[ VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION ] 를 해석해보며 어떤 방법론을 사용했는지 확인해보자.
AlexNet에서는 11x11, 5x5, 3x3 kernel을 이용하여 8층으로 구성했지만 VggNet은 그것보다 깊은 다양한 층을 쌓고 다양한 파라미터 개수에 실험을 수행하면서 오차를 구했다.
내용에 본격적으로 들어가는 [2-3]의 tanle-1 을 보기 전에 [2]장에 설명된 세팅값을 정리하고 들어가자.
▼ data - 224x224x3 (RGB)
▼ Preprocessing - training set 의 RGB의 평균값을 각 픽셀에 빼줌 (subtracting the mean RGB value)
▼ Conv layer - 3x3 filter or 1x1 filter which can be seen as a linear transformation of the input channels followed by non-linearity)
▼ stride - is fixed 1
▼ padding - 1 (해상도가 유지되기 위함, such that the spatial resolution is preserved )
// 필터를 거칠 수록 이미지 사이즈가 줄어들면 신경망을 깊게 만들 수 없기 때문
▼ Maxpooling - 2x2 , stride = 2 수행을 5번 반복
// 각 수행마다 이미지 사이즈는 1/2이 될 것이다.
▼ FC - 첫 번째, 두 번째 layer는 4096개 channel 과 활성화 함수로 ReLU 사용, 세 번째 layer는 1000개 channel을 가지며 Softmax 층이다.
▼ AlexNet에서 사용됐던 LRN (Local Response Normalisation)을 사용하지 않았다.
2 CONVNET CONFIGURATIONS
이제 [2-3] discussion의 table 1 을 살펴보자

왼쪽 A 에서 오른쪽 E로 갈 수록 11에서 19층까지 신경망의 깊이가 깊어진다. 오른쪽으로 갈 수록 한 층씩 신경망을 추가하고 변경한 과정은 Bold 처리하여 구분하기 쉽게 하였다.
7x7 filter를 쓰는 것보다 3x3 filter 사용하는 것의 장점은 다음과 같다.
1. 비선형 함수를 3번이나 사용할 수 있게되어 다양한 데이터에 유연하게 반응할 수 있다.
2. parameter 수가 감소한다. 3x3xC가 3개인 layer는 3(3^2xC^2) = 27C^2 이지만, 7x7인 layer는 (7^2 C^2) = 49C^2 이다.
파라미터의 개수를 81% 감소시킬 수 있다.
3 CLASSIFICATION FRAMEWORK
3-1 train
훈련시 설정값을 짚고 가자.
batch size : 256
momentum : 0.9
regularization : weight decay - 0.0005 (L2 regularization 적용)
dropout : 앞 2개의 fc layer 0.5 drop out 적용
learning rate : 0.01 으로 시작하며, validation set의 accuracy 향상이 멈출 때마다 learning late 10배 감소, 전체적으로 3번을 감소시킴.
최종적으로 370,000번의 연산, 74 epochs를 진행하고 훈련 종료.
weight의 initialisation은 굉장히 중요한데, 어디서 시작하냐에 따라 최솟값을 찾지 못하고 극솟값에서 빠져나올 수 없는 경우가 있기 때문이다. 그래서 table-1의 A 훈련의 경우에 한해, 초반의 4개 conv layer와 후반부의 3개 Fully connected layer에 초깃값 설정을 해줄 것인데, 평균 0, 표준편차 0.01 인 normal distribution에서 랜덤 샘플링을 했다 bias는 0이다. 나머지 layer는 무작위 값을 입력했다.
Augmentation
이미지를 얻어올 때, 1 SDG iteration마다 랜덤하게 crop한다. 추가적으로 수평 수직 변환, RGB변환을 수행한다. 논문에서는 크게 두 가지의 접근을 했다.
1. 이미지는 최종적으로 224x224의 형상으로 변환할 건데, 크기 224 이상의 모든 자료로 수행할 수 있으나 잘 알려진 사이즈는 256x256 과 384x384 이므로 위 두 개의 사이즈로 수행하고, 256과 384 형상의 이미지를 함께 학습한다면 384 이미지의 훈련속도 가속을위해 256 형상 이미지통해 사전 훈련된 weight를 이용하여 초기화 했다. learning late는 0.001로 설정했다.
2. 이번엔 고정된 이미지 크기가 아닌 256 ~ 512 중에서 무작위 선택을 하여 학습시켰다. 이 경우에는 364 형상의 이미지로 사전 훈련된 weight로 finetunning 하여 여러 크기의 이미지에 적용했다. 이 실험은 같은 224x224의 이미지더라도 사물이 차이하는 비율이 다를 수 있으므로 256!~512 크기의 이미지로 훈련하면 다양한 크기의 사물에 대처할 수 있게 된다.
3-1 testing
테스트 시에는 Fully connected layer의 첫 번째 층은 7x7 filter를 사용하고, 두 번째, 세 번째 Fully connected layer에서는 1x1 filter를 사용한다. 또한 test set에서도 augmentation을 적용하여 성능을 높이고 softmax layer를 통과 후 최종적인 확률을 구하게 된다.
4.1 SINGLE SCALE EVALUATION

table-3을 보며 알 수 있는 점을 살펴보자,
1. LRN (Local Response Normalisation)을 사용하지 않았다. 비록 얕은 층이지만 A와 A-LRN을 비교했을 때 성능개선 효과가 없거나 오히려 오류가 더 커졌음을 알 수 있다.
2. 신경망이 깊어짐에 비례하여 오류가 줄어듦을 관찰할 수 있다. 11~19layer까지 확인을 하였고 data set이 커질 수록 선형성은 더 뚜렷해진다.
2-1 테스트 B보다 C가 우수하다. C에서는 1x1 신경망이 추가되어 비선형성을 증가시켜줬기 때문이다.
2-2 테스트 C와 D는 신경망 깊이가 같지만 D의 성능이 더 우수하다. C는 1x1 conv layer를 포함하고 D는 3x3 layer로만 이루어져 있다. 1x1 layer는 비선형화를 하는 데 도움이 되지만 3x3으로 공간정보를 확보하는 것이 더 도움이 된다는 것을 알 수 있다.
2-3 테스트 B의 조건을 수정하여 다른 조건은 그대로 둔 채 filter size만 5x5로 바꿔서 실험했더니 오류가 7%더 높게 측정됐다.
// 공간정보를 확보하는 것보다 신경망을 깊게 쌓을 수 없는 것이 더 큰 factor일 것으로 추정.
3. 훈련단계에서 scale jittering을 사용한 것은 image size를 고정한 것보다 효과가 좋은 것을 볼 수 있다.
image jittering을 이해해보자 ! <이 부분은 다른 블로그를 거의 베껴온 수준이라 조만간 이미지를 다른 걸로 수정할 예정>

224이미로 만들기 위해, 256, 384 혹은 512 이미지까지 준비해보자.


이미지를 crop할 건데 주어진 이미지를 224의 크기로 여러 부분을 sampling한다.
test를 할 때 224의 이미지라도 사물이 80%를 채우고있을지 10%만 채우고 있을지에 따라 성능이 다르게 구현될 수 있다. 하지만 image jittering을 하여 사물의 크기에 따른 유연한 대처를 할 수 있게 된다.
// 여기서 crop과 아래 4-3 에서 언급될 multi-crop을 바꿔 설명한 건지는 확인해봐야할 것 같다.
https://codebaragi23.github.io/machine%20learning/1.-VGGNet-paper-review/
4.2 MULTI-SCALE EVALUATION
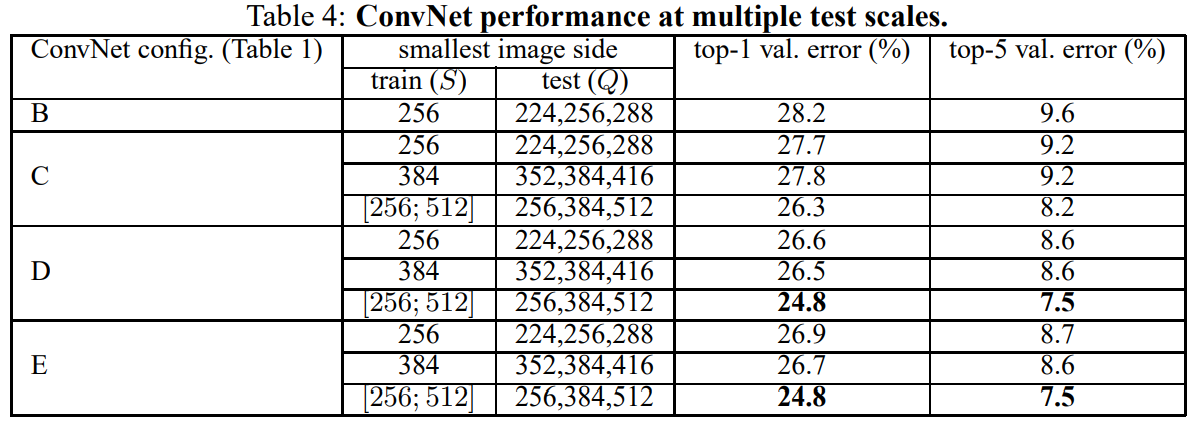
이번에는 train 단계 뿐만 아니라, test 단계에서도 다양한 이미지의 크기로 scale jittering을 했더니 더 좋은 성능이 나왔다.
4.3 MULTI-CROP EVALUATION

multi crop을 할 때 conv 은 zero padding을 하지만, dense evaluation 에서는 convolution 과 spatial pooling을 하기 때문에 경계가 자연스럽다. 상호 보완을 해줄 수 있기 때문에 앙상블에서 좋은 효과를 보인다.
// 사실 dense evaluation 이해 못했다.
4.4 CONVNET FUSION

지금까지 좋은 성능을 보인 지금까지의 모든 시도에서 마지막 한 방울까지 짜낸 결과다.
5 CONCLUSION
이 실험을 통해 신경망을 깊게 쌓는 방법과 그 방법의 유용성에 대해서 알아볼 수 있었다. 땅땅땅
'Ai > Notion' 카테고리의 다른 글
| Transformer 에서 cos, sin 함수를 사용한 이유(position encoding) (1) | 2023.10.17 |
|---|---|
| VIT (Vision Transformer) (0) | 2023.10.12 |
| Transformer (0) | 2023.10.12 |
| AlexNet architecture (1) | 2023.10.10 |
| LeNet-5 - A Classic CNN Architecture (1) | 2023.10.05 |




댓글