AlecNet의 특징점을 먼저 짚고 가자.
1. Training on multi-GPU
2. ReLU
3. Local Response Normalization
4. Overlapped Pooling
5. Reducing Overfitting
5-1 Data Augmentation
5-2 Dropout
1. Training on multi-GPU

AlexNet의 Architecture이다. 두 개의 GPU를 사용해 병렬학습으로 처리하는 것을 알 수 있다.
// 처음 제공한 이미지는 224x224가 아닌 227x227이 옳다.

5개의 convolution layer와 3개의 fully connected layer를 갖춰, 총 8층으로 이뤄져있다.

Conv-1에서 사용한 커널은 11x11x3이고 96개의 feature map을 만든다. 이때 만들어진 feature map들을 살펴보자.
위의 절반은 GPU1에서 학습한 색상과 관련 없는 정보의 결과이고
아래의 절반은 GPU2에서 학습한 색상과 관련 있는 정보의 결과이다.
// 이 실험을 할 당시, GTX580 두 대로 최대 효율을 뽑아내기 위해 병렬 처리 기법을 시도하고, 결과를 출력하기 위해 6일을 훈련시켰다고 한다. 정말 대단한 업적이다....
2.ReLU
LeNet에서는 Tanh를 썼지만 AlexNet에서는 ReLU를 사용한다.



Tanh는 비선형 함수의 특징을 사용하기 위해 차용했지만, 원점을 벗어난 영역에서는 기울기가 빠르게 작아져서 가중치 업데이트가 느린 것이 문제였다.
하지만 ReLU는 e^() 연산이 없고 기울기가 0이 되는 영역이 적기 때문에 가중치 업데이트가 Tanh에 비해 6배나 빠르다.
다만, ReLU의 중심이 원점이 아니기 때문에 zigzag 현상이 있다는 문제점은 있으나 사용시 얻는 이득이 훨씬 크기 때문에 보편적으로 쓰는 함수가 됐다.
3. Local Response Normalization
배치 정규화(batch normalization)의 등장으로인해 지금은 잘 사용하지 않는 기법이다.
ReLU는 입력값과 비례해 출력값을 결정한다. 그래서 너무 큰 입력값이 주어진다면 주변 값이 작더라도 convolution 연산을 할 때 sum은 큰 값이 나오고, 적절하지 않은 값임에도 True를 반환하는 over-fitting이 발생한다.
// 다른 train data가 주어진다면 정상작동 못할 것이다.
LRN은 이 문제를 해결하기 위해 한 영역에 유별나게 큰 값을 주변 혹은 같은 위치의 channel의 kerner을 제곱합(square sum) 하여 부드럽게 만든다.

\(a^i_{x,y}\)는 i번째 커널의 x,y 위치를 의미한다. \(b^i_{x,y}\)는 당연히 해당 위치의 결과가 된다.
N은 전체 커널 개수, n은 고려할 주변 커널 개수이고, alpha, beta, k 는 하이퍼파라미터이다.
발표한 논문에서는 k=2, n=5, a=10-4, b=-0.75가 적용되었다고 한다.
i = 3, n = 5 라면 필터를 정규화하기 위해 3번째 필터의 인접한 5개의 필터를 고려하겠다는 뜻이 된다.
공식을 이해하기 위해 예시 세 가지를 살펴보자.
ex 1 ) N = 50, i = 15, n=5
[ max(0, 15-5//2) , min(50-1, 15+5//2) , ] >> [ 15-5//2 ,15+5//2 ] >> [ 13 , 17 ]
50개의 커널 중 15번째 커널의 주변 5개 커널을 조사한다. 이때 13, 14, (15), 16, 17 커널을 계산한다.
ex 2 ) N = 50, i = 48, n = 5
[ max(0, 48-5//2) , min(50-1, 48+5//2) ] >> [ 48-5//2 , 50-1 ] >> [ 46 , 49 ] // 이때 index_max = 49이다.
50개의 커널 중 48번 째 주변 5개 커널을 조사한다. 46, 47, (48), 49 를 조사하고, 오른쪽 끝은 더 조사하지 않는다.
ex 3 ) N = 5, i = 3, n = 4
[ max(0, 3-4//2) , min(5-1 , 3+4//2) ] >> [ 3-4//2 , 5-1 ] >> [ 1 , 4 ] // 이때 inedex_max = 4이다.
5개의 커널 중 3번 째 주변 4개 커널을 조사한다. 1,2,(3),4를 조사한다.
4. Overlapped Pooling

일반적으로 kernel size는 stride와 같게 하여 겹치는 영역이 없게 하지만 AlexNet 개발자는 stride=3, kernel size=2로 하여 over lapping을 했다. 일반적인 pooling 성능과 비교할 때 error rate가 더 낮게 나온다. 지금은 흔히 사용하는 방법이다.
5. Reducing Overfitting
AlexNet 개발자들은 overfitting을 해결하기 위해 다음 두 가지 방법을 사용했다.
5-1 Data Augmentation

데이터가 부족하면 일반성을 갖추기 부족해지고, 편협한 자료에 훈련되어 overfitting 이 된다. Data Augmentation은 한정된 자료를 다양한 방법으로 변형하여 데이터 수를 증대시키는 방법이다. 실제로 학습단계에서 많이 사용되며, 예측 단계에서도 사용할 수 있다.
5-1 Dropout
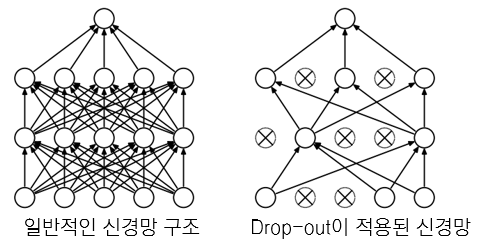
신경망을 훈련할 때, 모든 신경망을 사용하다보면 훈련이 덜 된 신경망이 있어도 잘 구동된다. 하지만 입력 데이터가 달라진다면 이야기가 달라질 수가 있다. 덜 훈련된 신경망도 학습시킬 수 있다.
'Ai > Notion' 카테고리의 다른 글
| Transformer 에서 cos, sin 함수를 사용한 이유(position encoding) (0) | 2023.10.17 |
|---|---|
| VIT (Vision Transformer) (0) | 2023.10.12 |
| Transformer (0) | 2023.10.12 |
| VggNet (0) | 2023.10.12 |
| LeNet-5 - A Classic CNN Architecture (1) | 2023.10.05 |




댓글